Departamento de Ciência da Computação
Universidade Federal de Minas Gerais
Belo Horizonte -- Brasil
| Aluno: | Adriano César Machado Pereira |
| E-mail: | adrianoc@dcc.ufmg.br |
| Data: | 11/Julho/2003 |
O objetivo deste trabalho é projetar e implementar um sistema de programas para recuperar ocorrências de padrões em arquivos constituídos de documentos, utilizando algoritmos lineares de busca sequencial.
O sistema de programas recebe do usuário uma cadeia de caracteres, se a busca é exata (![]() ) ou aproximada (
) ou aproximada (![]() ), e imprime todas as ocorrências do padrão no texto. Os seguintes algoritmos devem ser utilizados:
), e imprime todas as ocorrências do padrão no texto. Os seguintes algoritmos devem ser utilizados:
Encontrar as ocorrências de um determinado padrão em uma coleção de textos é um problema que ocorre com grande frequência em programas de edição de texto. Um padrão pode ser visto como uma cadeia de caracteres. Os caracteres são escolhidos de um conjunto denominado alfabeto. Em uma cadeia de bits, por exemplo, o alfabeto é {0,1}. Realizar pesquisa em cadeia de caracteres é uma aplicação importantes em diversos sistemas de computação, dos quais podemos citar: sistemas de recuperação de informação, edição de texto, estudo de sequências de DNA em biologia computacional, entre outros [5].
Podemos definir um texto como um arranjo ![]() de
comprimento
de
comprimento ![]() e que o padrão de reconhecimento também é um
arranjo
e que o padrão de reconhecimento também é um
arranjo ![]() de comprimento tal que
de comprimento tal que ![]() .
Consideramos também que
.
Consideramos também que ![]() e
e ![]() são caracteres retirados de um
alfabeto finito
são caracteres retirados de um
alfabeto finito ![]() .
.
Os algoritmos para casamento de padrão podem ter dois tipos de enfoques: casamento exato e casamento aproximado. Como o próprio nome indica, o casamento exato identifica a ocorrência exata do padrão pesquisado na coleção de textos. Já a abordagem aproximada possibilita encontrar o padrão pesquisado com erro, seja com algum caractere incorreto, a falta de um caractere ou até mesmo a existência de caractere extra. O mesmo procedimento é válido para uma pesquisa onde a quantidade de erros é superior a um.
O algoritmo mais simples para o casamento de padrões usa o processo de força bruta, que compara
cada substring de tamanho ![]() do padrão com a ocorrência
no texto. Um exemplo deste algoritmo é o seguinte [5]:
do padrão com a ocorrência
no texto. Um exemplo deste algoritmo é o seguinte [5]:
void ForcaBruta (TipoTexto T, int n, TipoPadrao P, int m) {
int i, j, k;
char *T, *P;
for (i = 0; i < n - m + 1; i++) {
for (j = 0, k = i; (j < m) && T[k] == P[j]; j++) k++;
if (j > m)
printf("Casamento do Padrao na Posição \%d\n", i);
}
}
O algoritmo apresentado não é eficiente, pois não usufruiu de nenhuma
otimização no processamento dos caracteres. Sua complexidade de tempo
é ![]() . Os Algoritmos implementados neste trabalho são mais
eficientes, conforme seré mostrado neste trabalho prático.
. Os Algoritmos implementados neste trabalho são mais
eficientes, conforme seré mostrado neste trabalho prático.
O algoritmo Boyer-Moore-Horspool executa uma busca sequencial no texto da coleção a ser pesquisada através de comparações realizadas da direita para a esquerda com relação ao padrão. Inicialmente é realizado um processamento prévio a fim de se obter o tamanho máximo dos deslocamentos sobre o texto da coleção a ser pesquisada.
Inicialmente o padrão é casado com o início do texto. O algoritmo prossegue comparando os caracteres do padrão da direita para a esquerda. Enquanto os casamentos vão ocorrendo o algoritmo continua realizando as comparações. Caso o padrão seja percorrido por completo, então indica que ocorreu um casamento exato. Caso não ocorra o casamento em dada iteração do algoritmo, a execução é interrompida e o padrão é deslocado sobre o texto de acordo com a máscara do próximo caractere do texto.
De acordo com o pré-processamento do padrão, o algoritmo realiza buscas por
ocorrências de padrões no texto. O algoritmo BMH consiste de uma simplificação
do algoritmo de Boyer-Moore [2]. O algoritmo BMH realiza
a comparação do padrão com o texto da direita para a esquerda. O procedimento é o
seguinte: o último caractere ![]() do padrão é alinhado com um caractere
do padrão é alinhado com um caractere ![]() do
texto e isso se repete, comparando
do
texto e isso se repete, comparando ![]() com
com ![]() ,
, ![]() com
com ![]() , e assim
por diante, até que
, e assim
por diante, até que ![]() seja diferente de
seja diferente de ![]() ou então o último caractere
do padrão tenha sido alcançado. Caso o caractere do padrão seja diferente do caractere
atual do texto, ou seja,
ou então o último caractere
do padrão tenha sido alcançado. Caso o caractere do padrão seja diferente do caractere
atual do texto, ou seja,
![]() , então o algoritmo deve definir qual
o caractere seguinte a ser comparado. Neste momento, ele utiliza então os valores
calculados na fase de pré-processamento.
, então o algoritmo deve definir qual
o caractere seguinte a ser comparado. Neste momento, ele utiliza então os valores
calculados na fase de pré-processamento.
O pré-processamento funciona da seguinte maneira: é construída uma tabela de
deslocamentos que estabelece, para cada caractere ![]() do alfabeto, de quantos
caracteres o ponteiro do texto deve ser deslocado para a direita de tal forma
que
do alfabeto, de quantos
caracteres o ponteiro do texto deve ser deslocado para a direita de tal forma
que ![]() fique alinhado com sua ocorrência no padrão. O algoritmo BMH sempre
utiliza o caractere do texto alinhado com o último caractere do padrão para
endereçar essa tabela de deslocamentos.
fique alinhado com sua ocorrência no padrão. O algoritmo BMH sempre
utiliza o caractere do texto alinhado com o último caractere do padrão para
endereçar essa tabela de deslocamentos.
A seguir é explicado o pré-processamento do algoritmo BMH. O código do pré-processamento é o seguinte:
/* BOYER-MOORE-HORSPOOL Algorithm */
1 void BMHPreprocess(char *pattern, int patternSize, int shiftTable[]) {
2 int i;
3 for (i = 0; i < ASIZE; ++i) shiftTable[i] = patternSize;
4 for (i = 0; i < patternSize - 1; ++i) shiftTable[pattern[i]] =
patternSize - i - 1;
5 }
O procedimento de pré-processamento recebe como parâmetro o padrão ![]() (representado
no código como pattern), um inteiro
(representado
no código como pattern), um inteiro ![]() (que define o tamanho do padrão - patternSize) e um vetor
(que define o tamanho do padrão - patternSize) e um vetor ![]() (que armazena os deslocamentos para cada caractere do alfabeto).
(que armazena os deslocamentos para cada caractere do alfabeto).
No primeiro anel do código (linha 3), o procedimento inicia o deslocamento
de todos os caracteres do alfabeto com o valor de ![]() . No anel seguinte (linha 4),
para cada caractere
. No anel seguinte (linha 4),
para cada caractere ![]() do padrão
do padrão ![]() , onde
, onde ![]() representa a posição do caractere
no padrão, seu deslocamento é calculado com o valor
representa a posição do caractere
no padrão, seu deslocamento é calculado com o valor ![]() . Caso um caractere ocorra mais
de uma vez no padrão, então seu deslocamento é definido de acordo com o deslocamento
de sua última ocorrência.
. Caso um caractere ocorra mais
de uma vez no padrão, então seu deslocamento é definido de acordo com o deslocamento
de sua última ocorrência.
A seguir é apresentado o código do BMH com as devidas explicações a respeito do mesmo.
1 void BMH(char *pattern, int patternSize, char *y, int n) {
2 int j, shiftTable[ASIZE];
3 char c;
/* Preprocessing */
4 BMHPreprocess(pattern, patternSize, shiftTable);
/* Searching */
5 j = 0;
6 while (j <= n - patternSize) {
7 c = y[j + patternSize - 1];
8 if (pattern[patternSize - 1] == c &&
memcmp(pattern, y + j, patternSize - 1) == 0){
9 if (oflag) imprimeOcorrencia(j);
10 }
11 j += shiftTable[c];
12 }
13 }
O procedimento ![]() recebe como parâmetro o padrão
recebe como parâmetro o padrão ![]() , um
inteiro
, um
inteiro ![]() que armazena o tamanho do padrão. A variável
que armazena o tamanho do padrão. A variável ![]() é a tabela de deslocamentos.
Na linha identificada por 04 o procedimento
é a tabela de deslocamentos.
Na linha identificada por 04 o procedimento ![]() é chamado
para calcular o deslocamento dos caracteres do alfabeto. O anel das linhas 06
a 12 realiza a seguinte computação: faz com que
é chamado
para calcular o deslocamento dos caracteres do alfabeto. O anel das linhas 06
a 12 realiza a seguinte computação: faz com que ![]() , uma variável que representa
o caracter receba o caracter atual do texto (linha 07); verifica se há correspondência
do caractere em
, uma variável que representa
o caracter receba o caracter atual do texto (linha 07); verifica se há correspondência
do caractere em ![]() com o caractere atual do padrão e compara o padrão com os caracteres
lidos do texto no momento; desloca a variável
com o caractere atual do padrão e compara o padrão com os caracteres
lidos do texto no momento; desloca a variável ![]() de acordo com a tabela de deslocamentos
de acordo com a tabela de deslocamentos
![]() .
.
Caso ocorra o casamento exato, identificado pelo teste feito na linha 08, então a ocorrência é impressa (desde que o flag de impressão - oflag - esteja habilitado).
Vale ressaltar que foi utilizada a função memcmp por questões de eficiência. Esta função compara os primeiros ![]() bytes de duas áreas de memória, retornando o valor 0 caso as áreas sejam idênticas, caracterizando o casamento.
bytes de duas áreas de memória, retornando o valor 0 caso as áreas sejam idênticas, caracterizando o casamento.
A análise do algoritmos de Boyer-Moore e Boyer-Moore-Horspool
depende apenas do padrão e do alfabeto em questão. A complexidade
de tempo e de espaço do BM para esta fase é ![]() . O pior
caso do algoritmo é
. O pior
caso do algoritmo é ![]() onde
onde ![]() é igual ao número total de
casamentos, o que torna o algoritmo ineficiente quando o número de
casamentos é grande. O melhor caso e o caso médio para o
algoritmo é
é igual ao número total de
casamentos, o que torna o algoritmo ineficiente quando o número de
casamentos é grande. O melhor caso e o caso médio para o
algoritmo é ![]() , ou seja, um resultado muito bom que equivale a
complexidade sublinear, conforme descrito em [5].
Já o algoritmo BMH possui complexidade de tempo e espaço
, ou seja, um resultado muito bom que equivale a
complexidade sublinear, conforme descrito em [5].
Já o algoritmo BMH possui complexidade de tempo e espaço ![]() para a
primeira etapa. Para a fase de pesquisa, o pior caso do algoritmo
é
para a
primeira etapa. Para a fase de pesquisa, o pior caso do algoritmo
é ![]() e o melhor caso é
e o melhor caso é ![]() . O caso esperado é
. O caso esperado é ![]() ,
também sublinear.
,
também sublinear.
O algoritmo Shift-And utiliza um autômato para representar
o padrão a ser procurado. Esse autômato representa uma transição
de estados, que ocorre quando um determinado caractere do padrão é
encontrado no texto. Um autômato ![]() que representa um padrão
que representa um padrão ![]() de tamanho
de tamanho ![]() possui
possui ![]() estados. A transição de um estado
estados. A transição de um estado ![]() para
para ![]() ocorre somente se o caractere
ocorre somente se o caractere ![]() do padrão for
igual ao caractere atual do texto. Quando o estado
do padrão for
igual ao caractere atual do texto. Quando o estado ![]() é alcançado indica que uma ocorrência do padrão foi encontrada no
texto.
é alcançado indica que uma ocorrência do padrão foi encontrada no
texto.
O algoritmo tira proveito do paralelismo de bits (técnica que
aproveita-se do paralelismo intrínsico das operações sobre bits)
para reduzir em até ![]() vezes o número de operações do algoritmo, onde
vezes o número de operações do algoritmo, onde ![]() representa o número de bits da palavra do computador. Esse algoritmo
simula esse paralelismo de bits através de um autômato não
determinístico.
representa o número de bits da palavra do computador. Esse algoritmo
simula esse paralelismo de bits através de um autômato não
determinístico.
O funcionamento do algoritmo é o seguinte: há um conjunto ![]() de bits,
onde
de bits,
onde ![]() é representado por uma máscara de bits
é representado por uma máscara de bits
![]() de todos os prefixos de P que casam com o texto já lido e, a cada caractere
lido, o algoritmo usufrui do paralelismo de bits para atualizar
de todos os prefixos de P que casam com o texto já lido e, a cada caractere
lido, o algoritmo usufrui do paralelismo de bits para atualizar ![]() .
.
Podemos explicar em detalhes o funcionamento do algoritmo Shift-And da seguinte maneira:
Para cada novo caractere lido ![]() o valor do novo conjunto é
inicializado através da fórmula:
o valor do novo conjunto é
inicializado através da fórmula:
![]()
Ou seja, a operação ![]() desloca todas as posições para a direita no passo
desloca todas as posições para a direita no passo
![]() , para marcar quais posições de
, para marcar quais posições de ![]() eram sufixos no passo
eram sufixos no passo ![]() .
A cadeia fazia também é marcada como um sufixo através do cojunto obtido
após a operação
.
A cadeia fazia também é marcada como um sufixo através do cojunto obtido
após a operação ![]() e
e ![]() e da operação de
e da operação de ![]() - tal operação permite
que um casamento possa iniciar na posição corrente do texto. Do conjunto
objtido até este ponto são mantidas somente as posições que
- tal operação permite
que um casamento possa iniciar na posição corrente do texto. Do conjunto
objtido até este ponto são mantidas somente as posições que ![]() casa
com
casa
com ![]() , o que é obtido por meio da operação
, o que é obtido por meio da operação ![]() dess conjunto de
posições com o conjunto
dess conjunto de
posições com o conjunto ![]() de posições
de posições ![]() em
em ![]() .
.
O algoritmo parece complexo, mas pode ser descrito em poucas linhas de
código utilizando a linguagem C. O autômato e seus estados podem ser
representados como uma sequência de bits e, somente com operações
![]() (
(![]() lógico aplicado bit a bit), é possível realizar o
caminhamento neste autômato.
lógico aplicado bit a bit), é possível realizar o
caminhamento neste autômato.
O algoritmo mantém um registrador, representado por uma sequência de ![]() bits, onde
bits, onde ![]() é o tamanho do padrão, que indica o estado atual do
autômato. Cada bit
é o tamanho do padrão, que indica o estado atual do
autômato. Cada bit ![]() deste registrador define se o estado
deste registrador define se o estado ![]() do autômato está ativo (1) ou inativo (0).
do autômato está ativo (1) ou inativo (0).
No autômato, o caminhamento é realizado utilizando as máscaras
pré-definidas para cada caractere ![]() do alfabeto. Através das
máscaras é possível saber que estados do autômato serão ativados
quando o caractere
do alfabeto. Através das
máscaras é possível saber que estados do autômato serão ativados
quando o caractere ![]() for encontrado no texto.
for encontrado no texto.
À medida que os caracteres do texto vão sendo alcançados,
as operações ![]() (bit a bit) são realizadas entre o
registrador e a máscara do caractere atual do texto. Se um
bit 1 alcança o último bit do registrador, então uma ocorrência do
padrão foi encontrada no texto.
(bit a bit) são realizadas entre o
registrador e a máscara do caractere atual do texto. Se um
bit 1 alcança o último bit do registrador, então uma ocorrência do
padrão foi encontrada no texto.
Para construção da máscara ![]() dos caracteres do alfabeto, ocorre o seguinte:
As máscaras de todos os caracteres do alfabeto são iniciadas como uma sequência
de 0. A partir daí, para cada ocorrência de um caractere
dos caracteres do alfabeto, ocorre o seguinte:
As máscaras de todos os caracteres do alfabeto são iniciadas como uma sequência
de 0. A partir daí, para cada ocorrência de um caractere ![]() na posição
na posição
![]() do padrão o i-ésimo bit de sua máscara
do padrão o i-ésimo bit de sua máscara ![]() deve receber o valor 1.
deve receber o valor 1.
Para realizar o caminhamento no autômato, as seguintes operações são executadas:
A seguir é apresentado o código do algoritmo Shift-And, explicando primeiro o pré-processamento e, em seguida, o processamento propriamente dito.
O método
![]() constrói as máscaras para todos os
caracteres do alfabeto e as armazena em um vetor (
constrói as máscaras para todos os
caracteres do alfabeto e as armazena em um vetor (![]() ). Neste
código, a máscara é elaborada de trás para frente (se a máscara
de um caractere é 1100, o resultado da sua construção utilizando o
método abaixo será 0011).
). Neste
código, a máscara é elaborada de trás para frente (se a máscara
de um caractere é 1100, o resultado da sua construção utilizando o
método abaixo será 0011).
/* Procedimento que realiza o pre-processamento do padrao, construindo
* as mascaras para cada caractere do alfabeto.
*/
01 void shiftAndPreprocess() {
02 int j, k=1;
03 char a;
04 for (j=0; j<m; j++){ // anel do pre-processamento
05 a=p[j]; // recupera o j-esimo caractere do padrão
06 ch[a]|=k; // atribui 1 ao j-esimo bit do j-esimo
// caractere do padrao
07 lastbit=k;
08 k<<=1;
09 }
10 }
Este algoritmo de pré-processamento percorre o padrão determinado
a máscara para cada caractere do padrão. Para definir um bit específico da
máscara de um caractere, uma operação ![]() é realizada entre a
máscara atual do caractere e a variável
é realizada entre a
máscara atual do caractere e a variável ![]() (linha 06).
A variável
(linha 06).
A variável ![]() armazena o bit que será definido como 1 na máscara do caractere
atual do padrão. Por isso, a cada iteração, ela é deslocada (shift) para
a esquerda (a máscara é construida invertida, conforme já foi relatado),
conforme operação realizada na linha 08.
A variável
armazena o bit que será definido como 1 na máscara do caractere
atual do padrão. Por isso, a cada iteração, ela é deslocada (shift) para
a esquerda (a máscara é construida invertida, conforme já foi relatado),
conforme operação realizada na linha 08.
A variável ![]() é utilizada para marcar representa o último bit do
registrado, ou seja, o bit que indica o casamento do padrão.
é utilizada para marcar representa o último bit do
registrado, ou seja, o bit que indica o casamento do padrão.
A seguir o algoritmo Shift-And (
![]() ) é listado e devidamente
explicado. Da mesma forma que as máscaras foram construidas, o
registrador que armazena o estado atual do autômato também será preenchido
invertido.
) é listado e devidamente
explicado. Da mesma forma que as máscaras foram construidas, o
registrador que armazena o estado atual do autômato também será preenchido
invertido.
/* Procedimento que realiza a busca exata de um padrao na
* colecao de textos.
*/
01 void shiftAndSearch() {
02 int i, r=0 // registrador que representa o automato
03 for (i=0; i < 256; i++) ch[i]= 0; // Incializa o alfabeto com mascara
// de valor zero (0).
04 shiftAndPreprocess(); // Realiza o pre-processamento do padrao
05 for (i=0; i<n; i++){
06 r=((r<<1) | 1) & ch[t[i]]; // Deslocamento para a esquerda (uma vez
// que o registrador esta invertido) e
// execucao de um "and" com a mascara do
// caractere corrente.
07 if ((r & lastbit)!=0) output(i-m+1); // Testa se o ultimo bit do
// registrador foi alcancado,
// que define o casamento
08 }
09 }
A seguir são feitas algumas explicações sobre o código apresentado. Na segunda
linha do código o registrador ![]() é inicializado com valor 0. Na linha seguinte
(03), todas as máscaras dos caracteres do alfabeto são incializadas com 0.
Já na linha de identificação 04, o procedimento
é inicializado com valor 0. Na linha seguinte
(03), todas as máscaras dos caracteres do alfabeto são incializadas com 0.
Já na linha de identificação 04, o procedimento
![]() , que
realiza o pré-processamento (conforme já explicado), é executado.
Enquanto existem caracteres no texto para serem lidos, o anel das linhas
identificadas com 05 a 08 faz o seguinte:
, que
realiza o pré-processamento (conforme já explicado), é executado.
Enquanto existem caracteres no texto para serem lidos, o anel das linhas
identificadas com 05 a 08 faz o seguinte:
O custo do algoritmo Shift-And é O(n), desde que as operações no calculo
de ![]() possam ser realizadas em O(1).
possam ser realizadas em O(1).
Nesta seção apresentamos o algoritmo Shift-And para casamento aproximado. Esse algoritmo, que foi proposto por Wu e Manber (1992), é uma extensão do algoritmo Shift And já explicado. Ele utiliza a mesma idéia, ou seja, construir um autômato que represente o padrão para guiar o processo de busca. A diferença entre ele e o anterior está na possibilidade de obter casamento com erros.
Este algoritmo abarca os seguintes tipos de erros durante o processamento:
De forma a possibilitar estes três tipos de erros, o autômato para casamento exato é incrementado com novos estados e transições e para isso são demandados novos registradores, um para cada quantidade de erros.
A implementação deste algoritmo é bastante parecida com a implementação do Shift-And para casamento exato. Ele também representa o autômato como uma seqüencia de bits e, através de operações lógicas bit a bit, realiza o caminhamento no autômato. Uma máscara também é definida para cada um dos caracteres do alfabeto
O pré-processamento continua inalterado, razão pela qual não será explicado novamente aqui.
A seguir é descrito o funcionamento desse algoritmo.
Para se definir o valor de um registrador ![]() (
(![]() ) deve ser
adotado o valor atual do registrador
) deve ser
adotado o valor atual do registrador ![]() e o valor
e o valor
![]() deste mesmo registrador anterior a modificação realizada. A expressão a seguir
fornece o cálculo do valor de
deste mesmo registrador anterior a modificação realizada. A expressão a seguir
fornece o cálculo do valor de ![]() .
.
Cada termo separado por um operador ![]() do lado direito desta
expressão representa uma possibilidade de transição, ou seja, indica
a possibilidade de um erro. A explicação desses termos é realizada a seguir:
do lado direito desta
expressão representa uma possibilidade de transição, ou seja, indica
a possibilidade de um erro. A explicação desses termos é realizada a seguir:
A seguir é apresentado o código C da implementação do algoritmo Shift-And para casamento aproximado. A mesma rotina de pré-processamente já descrita anteriormente é utilizada.
01 void aproximateShiftAndSearch() {
02 long i, j;
03 int *rs = (int*)malloc(sizeof(int)*(k+1)),
04 bit = 0 , rant, rnovo;
05 for (i=0; i < 256; i++) ch[i]= 0;// Inicializa o alfabeto com mascara
// de valor zero (0).
06 shiftAndPreprocess(); // Realiza o pre-processamento do padrao
07 for (i = 0; i <= k; i++){
08 rs[i] = bit;
09 bit = ((bit << 1) | 1);
10 }
11 for (i=0; i < n; i++){
12 rant = rs[0];
13 rnovo=((rant<<1) | 1) & ch[t[i]]; // Deslocamento para a esquerda
// (uma vez que o registrador
// esta invertido) e execucao
// de um "and" com a mascara
// do caractere corrente.
14 rs[0]=rnovo;
15 for(j = 1; j <= k; j++){
16 rnovo = ((rs[j] << 1)& ch[t(i)]) |
17 rant | ((rant | rnovo) << 1);
18 rant = rs[j];
19 rs[j] = rnovo;
20 }
21 if ((rnovo & lastbit)!= 0) output(i); // Testa se o ultimo bit do
// registrador foi alcancado,
// que define o casamento
22 }
23 }
Na terceira linha co código (identifica com 03), as ![]() posições
de memória alocadas são utilizadas para armazenar os valores dos
registradores (
posições
de memória alocadas são utilizadas para armazenar os valores dos
registradores (![]() ).
).
Já na linha identifica com 05, todas as máscaras dos caracteres do
alfabeto são incializadas com valor 0.
A linha 06 realiza o pré-processamento para montar as
máscaras. O anel que engloba as linhas 07 a 10 trata da inicialização
de cada registrador ![]() com seus
com seus ![]() bits menos significativos
com o valor 1.
bits menos significativos
com o valor 1.
As variáveis ![]() e
e ![]() são utilizadas no anel das
linhas 11 a 22, sendo que estas representam o valor anterior (
são utilizadas no anel das
linhas 11 a 22, sendo que estas representam o valor anterior (
![]() )
e o valor atual do registrador
)
e o valor atual do registrador ![]() , respectivamente.
Neste anel, para cada caractere do texto, o valor de cada registrador é
determinado assim:
, respectivamente.
Neste anel, para cada caractere do texto, o valor de cada registrador é
determinado assim:
Já a linha 21 realiza a verificação se o último bit do registrador
![]() é 1. Isso é feito para identificar se ocorreu o casamento aproximado
do padrão.
é 1. Isso é feito para identificar se ocorreu o casamento aproximado
do padrão.
Nesta seção apresentamos a implementação em Pascal dos algoritmos Shift-And para
casamento exato e casamento aproximado. O objetivo nesta parte extra do trabalho
foi implementar as operaões or, and e deslocamento (![]() ) da maneira
mais eficiente possível, porém mantendo a clareza no código. Nesse caso, o
compilador utilizado, o GPC(gnupascal), permite operações bit-a-bit
diretamente.
) da maneira
mais eficiente possível, porém mantendo a clareza no código. Nesse caso, o
compilador utilizado, o GPC(gnupascal), permite operações bit-a-bit
diretamente.
O código do procedimento de pré-processamento dos algoritmos de Shift-And em Pascal é listado a seguir:
CONST RegType Longint
RegType lastbit ; /marca o ultimo bit do registrador .
RegType ch [ASIZE] ;
procedure shiftAndPreprocess ()
var
k: RegType;
j: Integer;
a: String;
BEGIN
k := 1;
for j := 0 to m do
BEGIN
a := p[j] ;
ch[a] = ch[a] OR k ;
lastbit := k ;
k = k SHL 1;
END;
END;
O código do algoritmo Shift-And na linguagem Pascal é mostrado a seguir:
procedure shiftAndSearch()
var
i: Longint;
t: RegType;
BEGIN
r := 0; / Registrador
/ Inicializa todos os caracteres do alfabeto com 0
for i := 0 to 256 do ch[i] := 0;
shiftAndPreprocess();
i := 0;
while existeChar (i ) do
BEGIN
r := ((r SHL1) OR 1) AND ch[getChar (i )] ;
if ((r AND lastbit ) <> 0)outputOcurrence (i );
i := i + 1;
END;
END;
O código do algoritmo Shift-And aproximado na linguagem Pascal é mostrado a seguir:
procedure aproximateShiftAndSearch()
var
i ,j: Longint;
rs: RegType [0..50];
bit ,rant ,rnovo: RegType;
BEGIN
bit := 0
for i := 0 to 256 do ch[i] := 0;
shiftAndPreprocess();
for i := 0 to k do
BEGIN
rs[i] := bit ;
bit := ((bit SHL1) OR 1);
END;
for (i := 0; existeChar (i ); i ++)/i <n ; i ++)
BEGIN
rant := rs[0] ;
rnovo := ((rant SHL1) OR 1) AND ch[getChar (i)] ;
rs[0] := rnovo ;
for j := 1 to k do
BEGIN
rnovo := ((rs[j] SHL1) AND ch[getChar (i)] ) OR
rant OR ((rant OR rnovo ) SHL1);
rant := rs[j] ;
rs[j] := rnovo ;
END;
if ((rnovo AND lastbit ) <> 0)outputOcurrence (i );
END;
END;
Para exemplificar, um registro presente nestas coleções tem o seguinte formato:
<DOC> <DOCNO> WSJ890802-0125 </DOCNO> <DD> = 890802 </DD> <AN> 890802-0125. </AN> <HL> Inside Track: @ NCNB Director Sold Big Holding in July @ Worth $7.4 Million More 4 Weeks Later @ ---- @ By Alexandra Peers and John R. Dorfman @ Staff Reporters of The Wall Street Journal </HL> <DD> 08/02/89 </DD> <SO> WALL STREET JOURNAL (J) </SO> <CO> NCB BPCO TRN EGGS LABOR </CO> <IN> STOCK MARKET, OFFERINGS (STK) SECURITIES INDUSTRY (SCR) </IN> <TEXT> Even insiders make mistakes. Sometimes, big, fat, $7 million-dollar mistakes. ... </TEXT> </DOC>
De acordo com as instruções do trabalho, realizamos testes com as seguintes consultas para validar as implementações:
DCC UFMG dollar dia branco Macunaima administration Brazilian coffee New York Stock Exchange Manacapuru Canada Treasury Michael Gregory price index Uberaba
Conforme solicitado, foi feita uma interface similar a do agrep para o código implentado. A execução tem o seguinte formato:
usage: tp3.exe -f <input file> -p <pattern> -# <number of errors>
-a <algorithm> -c -t -o
onde as opções são as seguintes:
Para ilustrar o resultado da execução do algoritmo, realizamos a pesquisa do padrão Brazilian utilizando os três algoritmos implementado e a coleção do arquivo wsj89.
O resultado desta execução é exibido a seguir.
Algoritmo: bmh coluna 72: U.S. farmers have stepped up soybean sales recently, and beans from the Brazilian harvest have flowed onto world markets as well. coluna 16: @ To Japanese, Brazilian Firms </HL> coluna 181: One month after it spent US$350 million to acquire Quebec Cartier Mining Co., Dofasco Inc. sold half of its interest in the big iron ore mine to a Japanese trading company and a Brazilian industrial concern. coluna 159: Investors who bought the Brazil Fund in April when VBI Corp. announced a 9.9% stake would have lost a bundle; shortly after the news, the fund was rocked by a Brazilian market crisis, and the fund's shares plunged about 25%. coluna 59: As an example of what's available now, the dealer said, Brazilian coffee can be purchased for 73.50 cents a pound and Colombian at 86 cents. Total de ocorrencias: 5. ----- Algoritmo: sa coluna 72: U.S. farmers have stepped up soybean sales recently, and beans from the Brazilian harvest have flowed onto world markets as well. coluna 16: @ To Japanese, Brazilian Firms </HL> coluna 181: One month after it spent US$350 million to acquire Quebec Cartier Mining Co., Dofasco Inc. sold half of its interest in the big iron ore mine to a Japanese trading company and a Brazilian industrial concern. coluna 159: Investors who bought the Brazil Fund in April when VBI Corp. announced a 9.9% stake would have lost a bundle; shortly after the news, the fund was rocked by a Brazilian market crisis, and the fund's shares plunged about 25%. coluna 59: As an example of what's available now, the dealer said, Brazilian coffee can be purchased for 73.50 cents a pound and Colombian at 86 cents. Total de ocorrencias: 5. ----- Algoritmo: asa Padrao: Brazilian numero de erros: 1 coluna 79: U.S. farmers have stepped up soybean sales recently, and beans from the Brazilia n harvest have flowed onto world markets as well. coluna 80: U.S. farmers have stepped up soybean sales recently, and beans from the Brazilia n harvest have flowed onto world markets as well. coluna 23: @ To Japanese, Brazilian Firms </HL> coluna 24: @ To Japanese, Brazilian Firms </HL> coluna 188: One month after it spent US$350 million to acquire Quebec Cartier Mining Co., Dofasco Inc. sold half of its interest in the big iron ore mine to a Japanese t rading company and a Brazilian industrial concern. coluna 166: Investors who bought the Brazil Fund in April when VBI Corp. announced a 9.9% st ake would have lost a bundle; shortly after the news, the fund was rocked by a B razilian market crisis, and the fund's shares plunged about 25%. coluna 167: Investors who bought the Brazil Fund in April when VBI Corp. announced a 9.9% st ake would have lost a bundle; shortly after the news, the fund was rocked by a B razilian market crisis, and the fund's shares plunged about 25%. coluna 66: As an example of what's available now, the dealer said, Brazilian coffee can be purchased for 73.50 cents a pound and Colombian at 86 cents. coluna 67: As an example of what's available now, the dealer said, Brazilian coffee can be purchased for 73.50 cents a pound and Colombian at 86 cents. Total de ocorrencias: 10. -----
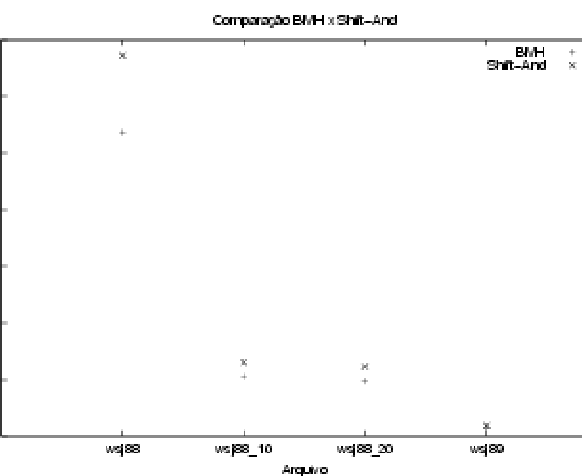
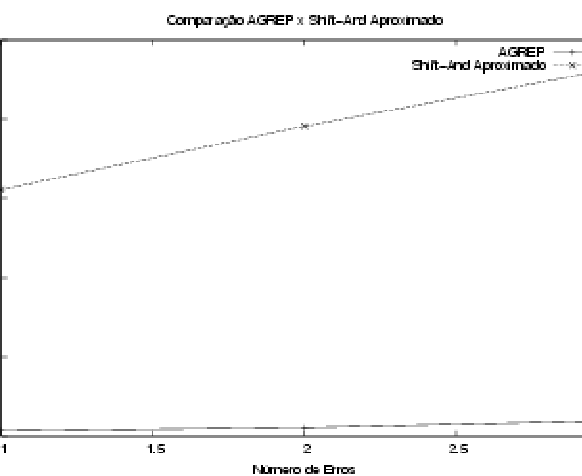
A seguir apresentamos os resultados empíricos dos experimentos realizados para avaliar o desempenho dos algoritmos, usando tempo de relógio. Realizamos experimentos para todos os algoritmos implementados.
 |
 |
A seguir serão apresentados todos esses resultados tabulados.
Para cada combinação de padrão, texto e algoritmo, foram executadas três baterias de experimentos das quais obteve-se a média dos tempos. As Tabelas 2, 3, 4 e 5 apresentam as medidas de tempo efetuadas para os algoritmos BMH e Shift-And.
|
|
|
Para cada combinação de padrão, texto e algoritmo, foram executadas três baterias de experimentos das quais obteve-se a média dos tempos. As Tabelas 6, 7, 8 e 9 apresentam as medidas de tempo efetuadas para o algoritmo Shift-And Aproximado, variando o número de erros.
|
|
|
|
Para cada combinação de padrão, texto e algoritmo, foram executadas três baterias de experimentos das quais obteve-se a média dos tempos. As Tabelas 10, 11, 12 e 13 apresentam as medidas de tempo efetuadas para o programa agrep, variando o número de erros.
|
|
|
|
A fim de avaliar o desempenho dos algoritmos implementados em Pascal foram feitos testes com a coleção do arquivo wsj88. O tempo medido nos experimentos foi muito superior, como mostra a Tabela 14.
Este resultado nãe era esperado, pois os valores medidos foram muito superiores aos códigos na linguagem C. Entretanto uma análise posterior mostrou que na realidade os altos tempos medidos se devem à manipulação do grande arquivo de entrada e rotinas de leitura de dados da linguagem Pascal. O tempo gasto pelas rotinas de busca é semelhante ao obtido nas implementações em C, entretanto as operações de entrada/saída atrapalharam originalmente esta análise.
A análise dos algoritmos de casamento exato de padrão possibilitou concluir que o BMH apresenta melhor eficiência do que o algoritmo Shift-And para a maioria dos padrões nos diversos tamanhos de arquivo.
Em alguns casos verificou-se o contrário, mas isso pode ser explicado pela sensibilidade dos experimentos, uma vez que por serem medidas de tempo muito curtas qualquer intrusão de outros processos na máquina pode gerar perturbações significativas. A repetição de alguns testes nos permitiu assegurar tal afirmação.
A análise dos algoritmos de busca aproximada Shift-And Aproximado e o programa agrep mostrou que ocorreu queda de desempenho quando o tamanho dos arquivos foram crescendo, assim como à medida que o número de erros foi sendo aumentado. Tais observações já eram esperadas.
O programa agrep, conforme já era esperado (pois utiliza um algoritmo mais eficiente do que o Shift-And Aproximado), apresentou melhor desempenho.
A análise dos resultados mostrou que os tempos em C e Pascal são bem parecidos. Confome já relatado, o tempo gasto pelas rotinas de busca é semelhante ao obtido nas implementações em C, entretanto as operações de entrada/saída atrapalharam originalmente esta análise, razão pela qual observa-se os altos tempos ilutrados na seção de experimentos.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "arquivo.h"
#include <unistd.h>
#include <sys/time.h>
#include <sys/resource.h>
#define MAX_LINE_SIZE 1000
#define MAX_FILENAME 256
int c [32];
char* p;
char line[MAX_LINE_SIZE];
int patternSize, n, lastbit, k = 0;
char ch [1000];
const int ASIZE = 1000;
int oflag= 0;
int matching_count = 0;
void imprimeOcorrencia(int j){
printf("Ocorrência na COLUNA: %d\n", j);
}
/* SHIFT AND Algorithm*/
void shiftAndPreprocess()
{
int j, k=1;
char a;
for (j=0; j<patternSize; j++)
{
a=p[j];
ch[a]|=k;
lastbit=k;
k<<=1;
}
}
void shiftAndSearch()
{
int i, r=0;
for (i=0; i < 1000; i++) ch[i]= 0;
shiftAndPreprocess();
for (i=0; i<n; i++)
{
r=((r<<1) | 1) & ch[line[i]];
if ((r & lastbit)!=0){
printf("*****************************************************\n");
if (oflag) imprimeOcorrencia(i-patternSize+1);
printf("LINHA DO CASAMENTO => %s",&line[0]);
printf("*****************************************************\n\n");
matching_count++;
}
}
}
void aproximateShiftAndSearch()
{
int i, *rs = (int*)malloc(sizeof(int)*(k+1)), bit = 0, rant, rnovo, j;
for (i=0; i < 256; i++) ch[i]= 0;
shiftAndPreprocess();
for (i = 0; i <= k; i++){
rs[i] = bit;
bit = ((bit << 1) | 1);
}
for (i=0; i<n; i++)
{
rant = rs[0];
rnovo=((rant<<1) | 1) & ch[line[i]];
rs[0]=rnovo;
for(j = 1; j <= k; j++){
//rnovo = ((rs[j] << 1)& ch[line[i]]) | rant | ((rant | rnovo) << 1);
// insercao // retirada ou substituicao
rnovo = ((rs[j] << 1)& ch[line[i]]) | rant | ((rant | rnovo) << 1);
rant = rs[j];
rs[j] = rnovo;
}
if ((rnovo & lastbit)!= 0) {
printf("*****************************************************\n");
if (oflag) imprimeOcorrencia(i);
printf("LINHA DO CASAMENTO => %s",&line[0]);
printf("*****************************************************\n\n");
matching_count++;
}
}
}
/* BOYER-MOORE-HORSPOOL Algorithm */
void BMHPreprocess(char *pattern, int patternSize, int shiftTable[]) {
int i;
for (i = 0; i < ASIZE; ++i) shiftTable[i] = patternSize;
for (i = 0; i < patternSize - 1; ++i)
shiftTable[pattern[i]] = patternSize - i - 1;
}
void BMH(char *pattern, int patternSize, char *y, int n) {
int j, shiftTable[ASIZE];
char c;
/* Preprocessing */
BMHPreprocess(pattern, patternSize, shiftTable);
/* Searching */
j = 0;
while (j <= n - patternSize) {
c = y[j + patternSize - 1];
if (pattern[patternSize - 1] == c &&
memcmp(pattern, y + j, patternSize - 1) == 0){
printf("*****************************************************\n");
printf("LINHA DO CASAMENTO => %s",y);
if (oflag) imprimeOcorrencia(j);
printf("*****************************************************\n\n");
matching_count++;
}
j += shiftTable[c];
}
}
int main(int argc, char **argv, char * env[ ]){
/* Declaracao de variaveis */
int index;
int c;
char *algorithm;
char *in;
FILE *fin;
struct timeval begin;
struct timeval end;
long seg, microseg, tempoSegundos, tempoMicroSegundos = 0.0;
int tflag = 0;
int cflag = 0;
int errflg = 0;
opterr = 0;
algorithm = "lixo";
while ((c = getopt (argc, argv, "f:p:#:c::t::hoa:")) != -1)
switch (c){
case 'a':
algorithm = optarg;
break;
case 'f':
in = optarg;
break;
case 'p':
p = optarg;
break;
case '#':
k = atoi(optarg);
break;
case 'c':
cflag = 1;
break;
case 'o':
oflag = 1;
break;
case 't':
tflag = 1;
break;
case 'h':
fprintf(stderr, "help command\n---- -------\nusage: tp3.exe -f <input file>
-p <pattern> -# <number of errors> -a <algorithm> -c -t -o\n\n");
exit(2);
case '?':
if (isprint (optopt)){
fprintf (stderr, "Unknown option `-%c'.\n", optopt);
fprintf(stderr, "\nusage: tp3.exe -f <input file> -p <pattern>
-# <number of errors> -a <algorithm> -c -t -o\n\n");
exit(2);
}else{
fprintf (stderr, "Unknown option character `\\x%x'.\n", optopt);
}
return 1;
default:
abort ();
}
for (index = optind; index < argc; index++)
printf ("Non-option argument %s\n", argv[index]);
if (tflag) gettimeofday(&begin, (void*)0);
patternSize = strlen(p);
fin = abreArquivo(in);
if (cflag) matching_count = 0;
printf ("ALGORITMO %s \n", algorithm);
if (!strcmp(algorithm,"bmh")){
while(fgets(line, MAX_LINE_SIZE, fin)) {
n = strlen(line);
BMH(p, patternSize, line, n);
}
}else if (!strcmp(algorithm,"sa")){
while(fgets(line, MAX_LINE_SIZE, fin)) {
n = strlen(line);
shiftAndSearch ();
}
}else if (!strcmp(algorithm,"asa")){
while(fgets(line, MAX_LINE_SIZE, fin)) {
n = strlen(line);
aproximateShiftAndSearch ();
}
}else{
fprintf (stderr, "Favor definir um algoritmo de casamento de padroes.
As opcoes sao\n");
fprintf (stderr, "=> bmh: Algoritmo de Boyer-Moore-Horspool para
casamento exato de padroes\n");
fprintf (stderr, "=> sa: Algoritmo Shift-And para casamento exato
de padroes\n");
fprintf (stderr, "=> asa: Algoritmo Shift-And para casamento
aproximado de padroes\n");
exit(2);
}
printf ("ALGORITMO %s \n", algorithm);
if (tflag) gettimeofday(&end, (void*)0);
// Recebe o tempo necessario para ordenar o arquivo
if (tflag){
seg = end.tv_sec - begin.tv_sec;
microseg = end.tv_usec - begin.tv_usec;
tempoMicroSegundos = (seg * 1000000 + microseg);
tempoSegundos = tempoMicroSegundos / 1000000;
}
//printf("Tempo de CASAMENTO: %d\n", tempoMicroSegundos);
printf("ALGORITMO: %s\n", algorithm);
if (cflag) printf("Quantidade de CASAMENTOS: %d\n", matching_count);
if (tflag) printf("Tempo de CASAMENTO: %d segundos\n", tempoSegundos);
fechaArquivo(fin);
return 0;
}
This document was generated using the LaTeX2HTML translator Version 2K.1beta (1.48)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -split 0 trabalho3
The translation was initiated by Adriano Cesar Machado Pereira on 2003-07-11