Resumo
O objetivo deste trabalho é validar com maior precisão o modelo analítico proposto no trabalho em [01]. Analisamos estatisticamente as variáveis do sistema, simulamos o processamento seqüencial das consultas e comparamos os tempos da simulação com os tempos reais amostrados. De acordo com os experimentos realizados concluímos que o modelo analítico representa com maior precisão o comportamento do sistema real, apresentando um desvio relativo de 4.8%.
1. Introdução
Sistemas de recuperação de informação estão cada vez mais necessitando de consultas rápidas e eficientes. Isto ocorre graças ao crescimento dos bancos de dados textuais, e ao rápido incremento do número de usuários o que gera um maior número de consultas. Devido a estes fatores, estes sistemas estão se voltando a técnicas paralelas e distribuídas para armazenamento e busca.
Para encontrar rapidamente documentos, os sistemas de recuperação de texto constroem índices invertidos no disco. As duas estratégias tradicionais para distribuir as coleções de índices foram propostas no trabalho em [02]. São eles o particionamento de Índice Local (IL) e o particionamento de Índice Global Lexicográfico (IGL). No IL, os documentos no banco de dados texto são distribuídos entre os processadores e cada processador gera um arquivo invertido para seus documentos. No IGL um arquivo invertido é gerado para todos os documentos no banco de dados texto e as listas invertidas são distribuídas entre os processadores de acordo com a ordem lexicográfica dos termos.
Partindo destas propostas, o trabalho em [01] apresenta uma nova forma de distribuir as coleções de índices entre vários computadores, chamada de Índice Global Randômico (IGR), que também pode ser vista em [05] e [06]. Nesta proposta um arquivo invertido é gerado para todos os documentos no banco de dados textual e as listas invertidas são divididas em blocos do mesmo tamanho. Após isso, os processadores são selecionados randomicamente para possuir cada bloco das listas invertidas. No trabalho em [01] é realizada uma validação do modelo analítico utilizando os valores médios das variáveis obtidos através de amostragens.
O presente trabalho, feito em conjunto com Badue, valida um modelo analítico para um sistema de processamento de consultas fazendo inicialmente uma análise estatística das variáveis pertencentes ao sistema. Em seguida realizamos a simulação e, por fim, comparamos os resultados obtidos com os tempos reais amostrados.
O corrente trabalho apresenta a seguinte estrutura. Na seção 2, falaremos sobre as arquiteturas usadas em sistemas de recuperação de informação. Na seção 3, mostraremos quais as propostas de particionamento de índices. Na seção 4, discutiremos as formas de processamento das consultas. Na seção 5, daremos uma definição sobre modelos analíticos. Na seção 6, faremos a validação do modelo proposto. E por fim, na seção 7 mostraremos as conclusões obtidas e possíveis trabalhos futuros.
2. Arquitetura do sistema de recuperação de informação
É utilizado um modelo de redes de estações de trabalho que pode ser vista na figura 2.1. Neste modelo as estações são fortemente acopladas por switches. Cada estação tem sua própria memória local e disco local. As vantagens desta arquitetura é que toda a comunicação entre os processadores é feita através de mensagens, o que elimina a interferência do sistema operacional ao controle de memória dos processos; e os discos são acessados diretamente pelo processador sem utilizar a rede.
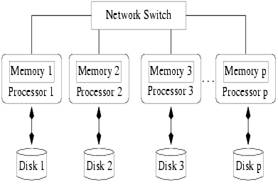
Figura 2.1: Modelo de rede de estações de trabalho
Além disso, o sistema de recuperação de informação adota o paradigma cliente-servidor que consiste de um conjunto de processadores e um broker, que é responsável por aceitar a consulta vinda dos clientes, distribuir estas consultas entre os processadores e receber os resultados intermediários dos procesadores formando a resposta final para os clientes. Cada processador e o broker rodam em uma máquina separada. Este paradigma está descrito na figura 2.2.
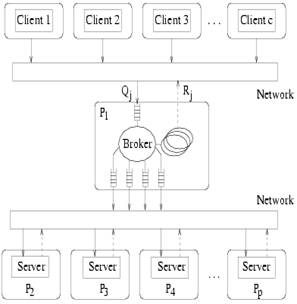
Figura 2.2: Paradigma cliente-servidor
3.Particionamento do índice
Como falamos anteriormente, existem três esquemas de particionamento. Nesta seção iremos detalhar cada um dos esquemas.
Índice Local (IL): neste caso, cada processador gera uma lista de arquivos invertidos para seus documentos locais.
Índice Global Lexicográfico (IGL): neste caso é gerado um arquivo invertido global e as listas invertidas são distribuídas para os processadores em ordem lexicográfica.
Índice Global Randômico (IGR): neste caso, um arquivo invertido é gerado para todos os documentos no banco de dados texto e blocos de tamanhos fixos das listas invertidas são distribuídos randomicamente entre os processadores.
4.Processamento das consultas
Nesta seção, discutiremos as características do sistema de processamento distribuído de consultas, que consiste de um conjunto de processadores e um broker que processa as consultas. Neste contexto, iremos mostrar como cada estratégia de particionamento faz este processamento.
Índice Local (IL): neste caso o broker envia as consultas para todos os processadores. Cada processador recupera os documentos relacionados com cada consulta na sub-coleção local e os ordena. Após isso seleciona um número de documentos do topo da lista e os retorna para o broker como a resposta local. O broker, por sua vez, usa um multiway merge [07] para fundir os conjuntos de respostas locais e produzir a resposta final ordenada.
Índice Global Lexicográfico (IGL): aqui o broker verifica quais processadores possuem as listas invertidas referentes aos termos da consulta, quebra a consulta em sub-consultas e as envia para os respectivos processadores. Ao receber uma sub-consulta o processador recupera os documentos relacionados a esta sub-consulta e os ordena. Após isso seleciona um número de documentos do topo da lista ordenada e envia para o broker como sua resposta local. Ao receber a resposta o broker adiciona os pesos (grau de similaridade com a consulta) dos documentos que estão presentes em mais de uma resposta local e os ordena usando o algoritmo quicksort para produzir a resposta final.
Índice Global Randômico (IGR): neste caso, o broker determina que processadores possuem os blocos das listas invertidas relativas aos termos da consulta, quebra a consulta em sub-consultas e as envia para os respectivos processadores. Ao receber a sub-consulta o processador recupera os documentos relacionados em um sub-conjunto local de blocos de listas invertidas e os ordena. Após isso ele seleciona um número de documentos do topo da lista e os retorna para o broker como o conjunto de respostas locais. O broker adiciona os pesos (grau de similaridade com a consulta) dos documentos que estão presentes em mais de uma resposta local e faz uma ordenação usando o algoritmo de quicksort para gerar a resposta final ordenada.
5. Modelo analítico
Para prever o desempenho de um sistema cliente/servidor, é necessário decidir o modelo que melhor o representa. Modelos analíticos são baseados em um conjunto de fórmulas e/ou algoritmos computacionais utilizados para gerar métricas de desempenho a partir de parâmetros do modelo. Além disso, existem modelos de simulação que são programas que imitam o comportamento de um dado sistema. Baseados nestes modelos, podemos obter medidas como médias ou desvios padrão, e até mesmo distribuições de métricas de desempenho [04].
Estes modelos podem ser desenvolvidos sob diferentes níveis de detalhamento. Dentre os níveis possíveis destacam-se dois: o modelo de desempenho ao nível de sistema e o modelo de desempenho ao nível de componentes.
No modelo de desempenho ao nível de sistema, o sistema é modelado como uma “caixa preta”. Os detalhes sobre o sistema não são explicitados e o único fator considerado é a função de throughput. Para o modelo ao nível de componentes, são considerados os diferentes recursos do sistema e o modo como eles são usados pelas diferentes requisições. Processadores, discos e redes são explicitamente considerados pelo modelo.
O modelo ao nível de componentes considera um sistema computacional como uma Queuing Network, sendo que cada recurso do sistema representa uma fila. Estas filas podem ser limitadas ou não quanto ao número de requisições. Para filas limitadas, uma análise pode ser feita a partir das equações que representam o tempo de espera, a taxa de throughput e o tamanho da fila.
Os trabalhos [01] e [03] utilizam a modelagem ao nível de componentes para representar os recursos consumidos no broker para escalonamento das consultas e intercalação dos resultados intermediários retornados pelos processadores, e os recursos consumidos em cada um dos processadores para leitura do índice, recuperação e ordenação dos documentos.
O modelo analítico proposto segue o padrão ao nível de componentes . São descritas cinco fases principais durante o processamento distribuído das consultas. Estas fases são:
· Leitura das listas invertidas dos discos.
· Acumulação dos pesos (grau de similaridade com a consulta) dos documentos.
· Ordenação do conjunto local de respostas.
· Transferência dos conjuntos locais de respostas para o broker.
· União dos conjuntos locais de respostas no broker.
Uma descrição mais exata sobre as variáveis utilizadas na modelagem pode ser encontrada em [01] e [03].
6. Validação do modelo analítico.
Validar o modelo analítico significa determinar se o modelo apresentado é uma representação precisa do sistema real.
A validação segue dois objetivos:
- Obter um modelo que represente o sistema real com suficiente aproximação para que possa ser utilizado em sua substituição para efeitos de experimentação.
- Aumentar a credibilidade do modelo até um nível aceitável para que possa ser utilizado por quem deve tomar as decisões.
6.1. Metodologia
A metodologia seguida para realizar esta validação pode ser dividida em duas grandes etapas.
Análise das variáveis
Nesta etapa, foram obtidas amostragens das diferentes variáveis a serem analisadas. Uma vez gerados os gráficos tentamos identificar alguma distribuição teórica que possa representar o comportamento destas variáveis. No caso de não encontrarmos uma distribuição teórica adequada, utilizaremos a mesma distribuição empírica encontrada para realizar a simulação.
As variáveis analisadas foram; ts representa o tempo de leitura para ler um bloco de 4 KB do disco incluindo o tempo de busca; tr representa o tempo de leitura para ler um bloco de 4 KB do disco excluindo o tempo de busca; th representa o tempo para inserir ou acumular um par <documento, similaridade> em uma tabela hash; tc representa o tempo de executar uma operação de comparação ou swap durante a classificação dos documentos.
As abordagens realizadas para estas variáveis foram:
· ts, utilizamos sua distribuição acumulada para gerar valores aleatórios que obedecem à distribuição encontrada.
· tr, devido ao comportamento desta variável, a simulação se realizará utilizando o parâmetro moda encontrado.
· th, esta variável apresenta uma relação linear com a variável número de documentos a serem inseridos. Por causa disto, encontramos a equação de regressão linear que representa esta relação, e a utilizamos para a simulação.
· tc, como no caso anterior, esta variável apresenta uma relação linear com o número de documentos a serem ordenados. Da mesma forma, encontramos a equação de regressão linear, e a utilizamos para a simulação.
Para exemplificar a análise das variáveis tomemos o ts e o tr.
No caso da variável ts, uma vez realizada a amostragem, podemos observar que o histograma encontrado, figura 6.1, apresenta uma forma similar a uma distribuição normal, mesmo assim não conseguimos ajustar nenhuma distribuição teórica. Por este motivo utilizaremos a mesma distribuição encontrada para a geração desses valores aleatórios.
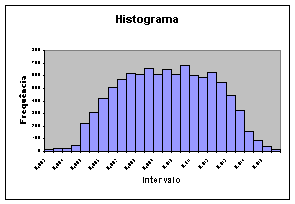
Figura 6.1: Amostragem da variável ts
Para realizar a geração destas variáveis aleatórias procedemos da seguinte forma,
· Obtivemos a distribuição acumulada apresentada na figura 6.2;
· Geramos números pseudoaleatórios;
· Encontramos o intervalo que contém o número obtido, e o valor da variável aleatória gerada será o valor do intervalo.
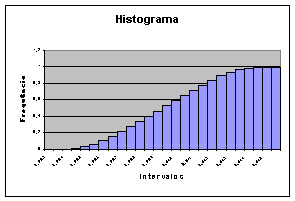
Figura 6.2: Distribuição acumulada
Para gerar esses valores implementamos um algoritmo e geramos um grande número de variáveis para verificar, através de um teste de hipótese, se esse algoritmo gera realmente esse tipo de distribuição.
No caso da variável tr, depois de realizada a amostragem foi obtido o seguinte histograma, figura 6.3.
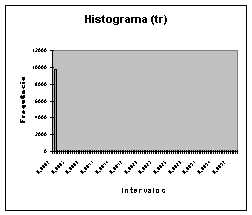
Figura 6.3: Amostagem da variável tr.
No histograma podemos observar que evidentemente não é preciso simular esta varíavel ja que seu comportamento é muito constante. O cuidado que devemos tomar neste caso é o de não utilizar a média como parâmetro para sua simulação ja que ela é muito afetada por valores extremos.Para evitar este tipo de problemas podemos utilizar a mediana ou a moda.
Simulação dos dados e comparação dos resultados
Uma vez concluída a primeira etapa, para cada uma das variáveis, estamos habilitados a realizar a simulação das diferentes variáveis, para poder comparar os tempos obtidos na simulação, como os tempos obtidos do sistema real.
Para esta etapa, utilizamos uma coleção de 20 GB de páginas coletadas pelo mecanismo de busca TodoBR [08], e um conjunto de 3.500 consultas submetidas a ele. As consultas foram executadas em um processador seqüencial, os valores das variáveis foram coletados e os tempos reais das buscas foram medidos.
Para manter uma boa precisão e filtrar interferências provocadas pela medição de tempo individual das consultas, utilizaremos como unidade de comparação a soma do tempo de 50 buscas. Esta decisão não prejudica a análise realizada, mas simplesmente melhora a precisão da medição dos tempos reais.
Em seguida mostraremos, na figura 6.3, um gráfico que apresenta em forma conjunta os dados reais e simulados.
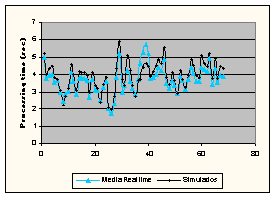
Figura 6.4: Dados reais versos dados simulados
Nesta figura, podemos observar como o modelo analítico continua representando bem o modelo real, mesmo tendo inserido aleatoriamente as variáveis geradas.
O desvio padrão relativo, entre os tempos reais e os tempos simulados, foi apenas de 4.8%.
7.Conclusões e trabalhos futuros
Neste trabalho realizamos um estudo estatístico, das variáveis envolvidas no processamento das consultas. Também foram validadas as relações entre as variáveis pertencentes ao modelo analítico, comparando valores de tempos reais amostrados com os tempos obtidos através da simulação, apresentando como resultado um desvio relativo entre os tempos reais e os tempos simulados, de 4.8%.
Podemos observar que houve um pequeno incremento no desvio relativo se comparado ao resultado obtido em [01]. Isto se deve ao fato de incorporar ao modelo variáveis geradas aleatoriamente, mas isto também oferece mais credibilidade e precisão, já que também simula as variações aleatórias que o sistema real possui de forma intrínseca.
Trabalhos futuros incluem a realização e validação de um modelo que permita simular o processamento de consultas numa arquitetura distribuída. Na simulação poderemos comparar as estratégias de partição dos índices IL, IGL e IGR variando não somente a taxa de chegada das consultas, mas também variando o comportamento das mesmas.
Referência
|
[01] |
C. S. Badue, N. Ziviani, W. Meira, B. Ribeiro-Neto, and R. Baeza-Yates. Balanced Distributed Query Processing Using a Random Layout. Submitted to CIKM, 2002. |
|
[02] |
A. Tomasic and H. Garcia-Molina. Performance of inverted indices in shared-nothing distributed text document information retrieval systems. In Proceedings of the Second International Conference on Parallel and Distributed Information Systems, pages 8 – 17, San Diego, California, U.S.A., 1993. |
|
[03] |
J. S. Santiago, O.F. Oliveira, R. P. Couto, W. D. Maciel. Análise e Modelagem de Desempenho de Sistemas Distribuídos de Recuperação de Informação. Projeto do Curso "Análise e Modelagem de Desempenho", Ministrado por Virgílio A. F. Almeida, Departamento de Ciência da Computação – Universidade Federal de Minas Gerais, Fevereiro de 2002. |
|
[04] |
V. A. F. Almeida, D. A. Menascé. Capacity Planning for Web Performance – Metrics Models & Methods. Prentice-Hall 1998. |
|
[05] |
W. Xi1, O. Sornil, M. Luo and E. A. Fox. Hybrid Partition Inverted Files: Experimental Validation. Em Proceeding of the 6th European Conference on Research and Advanced Technology for Digital Libraries (ECDL2002), Roma, Itália, 16 a 18/09/2002. |
|
[06] |
O. Sornil, E. A. Fox. Hybrid Partitioned Inverted Indices for Large-Scale Digital Libraries. Em Proceedings of International Conference on Asian Digital Libraries, ICADL'2001, Bangalore, India, 10 a 12/12/2001 |
|
[07] |
I. H. Witten, A. Moffat, and T. C. Bell. Managing Gigabytes – Compressing and Indexing Documents and Images. Morgan Kaufmann Publishers, Inc., Second edition, 1999. |
|
[08] |
TodoBR. Página principal: http://www.todobr.com.br. Em 20 de Setembro de 2002 |