|
David Patrício Viscarra del Pozo
Rodrigo Pereira Braga
Projeto e Análise de Algoritmos
Departamento de Ciência da Computação
Universidade Federal de Minas Gerais
Belo Horizonte -- Brasil
deivid1,rpereira@dcc.ufmg.br
Os interpretadores PS podem gerar caracteres que não existem no arquivo fonte. Além disso as quebras de linha e de parágrafos são parte da apresentação gráfica e devem inferir a partir da posição do fragmento.
Os programas apresentados neste artigo mostram métodos para utilizar um interpretador de PS, mas redefine várias operações e simple heurísticas para localizar quebras de palavras e de linhas. Os testes sobre o melhor programa foram executados no artigo para criar um índice de 40.000 relatórios técnicos (34GB de PS)[NMRW98].
Este trabalho envolve não somente converter texto em padrões diferentes, mas também relaizar alguns experimentos e validar o uso de uma heurística para reconhecimento de texts em arquivos PS.
São descritas algumas heurísticas para detecção de quebras de linhas e de palavras, pois a diferença de espaçamento entre caracteres depende do tamanho da fonte. Analisaremos uma heurística simples mais adiante. Em suma, utilizaremos várias técnicas para manter o formato de páginas o mais próximo possível do original.
Analisaremos diante dos programas testados os aspectos de robustez e rapidez, para isto, explicaremos abaixo os problemas encontrados, as soluções dispostas na literatura e uma comparação entre elas.
Na extração textos de arquivos PS, aparecem alguns problemas em níveis diferentes, por exemplo: no nível de abstração, PS é uma linguagem de programação, a saída não pode ser determinada por uma leitura no arquivo fonte; no nível pragmático, a maioria dos documentos PS têm uma estrutura computacional ordenada que faz com que a saída textual esteja disponível imediatamente, mas fragmentada e misturada com outros textos que não formam o texto original.
Como o PS é uma linguagem de programação, sua saída não pode ser obtida via uma leitura do texto no arquivo fonte. O problema que enfrentamos é decorrente do nosso trabalho não ser uma simples conversão de formato, mas a predição de um resultado de um programa.
Para exemplificar, considere o programa em PS na figura 2(a). Este exemplo gera a seqüência de Fibonacci e no caso, retorna o sexto item da mesma. O programa não possui nenhum número 8 no código, entretanto a saída possui o caracter 8 (figura 2(b)), logo devemos executar o PS direcionando a saída para gerar texto ASCII ao invés de gráfico.
Na figura 3 podemos encontrar outro problema. Os caracteres a serem mostrados na página são colocados entre parêntesis no arquivo fonte. Uma aproximação para extrair este texto, seria simplesmente extrair e concatenar estes grupos de caracteres. Entretanto dois problemas aparecem nesta solução: o primeiro é decorrente de algumas formas de representação de dados interno ao PS serem feitas entre parêntesis também, nomes de arquivos, fontes e outros;o segundo é que a divisão do texto em palavras não é aparente, pois espaços são implicitamente posicionados na página, cada parêntesis pode definir somente parte de uma palavra (fragmento), logo devemos decidir quais fragmentos devem ser concatenados; este inconveniente é tratado no trabalho com a análise da heurística simples.
Uma solução prática é redefinir a operação show, que agora ao invés de imprimir sua saída na tela como gráfico, imprimirá em um texto simples sem formatação. Na figura 4(a) do lado direito, podemos perceber a redefinição da função /show por /show {print} def e no lado esquerdo vemos o resultado. Deste modo, resolvemos um problema demonstrados anteriormente: obtemos o texto útil e não os textos de utilização interna do PS.
Continua o problema de identificar as palavras completas em meio aos vários fragmentos e inserir espaços entre estas palavras, para isto utilzamos a nova definição na figura 4(b) que insere um espaço entre os fragmentos: /show {print ( ) print} def.
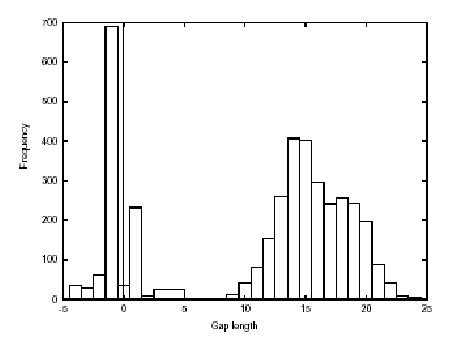
Espaços aparecem entre palavras que não deviam possuir espaço, como m ultiple ou imp ortan t, mas como vimos na seção anterior, um fragmento não determina uma palavra. Isto acontece, pois quando ``justificamos'' o texto, a linguagem insere espaços (não o caracter espaço, mas pontos de impressora1vazios) entre as palavras. A análise feita por [NMRW98] prova que em uma base de dados de 34 GB de PS, se comporta bem um limiar de 5 pontos para diferenciar um espaço inserido pela ``justificação'' ou um caracter espaço, podemos observar em figura 5.
Pela figura 4(c) percebemos a modificação na implementação do show para acrescentar esta folga de 5 pontos a coordenada horizontal do texto. A linha: systemdict /show get exec utiliza a definição do /show interpretar o arquivo utilizando como parâmetro a nova string. Podemos ver pela figura 4(c) no lado direito que o texto possui os espaçamentos corretos. Apesar de existir o problema com o caracter emphfl", que é representado pelo símbolo §, estes erros são tratados na próxima seção.
A solução utilizada para estes exemplos apresenta resultados muito bons, mas existem inconvenientes que podem ser resolvidos com heurísticas. Estes inconvenientes incluem: o tratamento do limiar quando a fonte é pequena ou grande demais, distinguir entre quebras de parágrafos e de linha, lidar com caracteres não-ASCII, retirar os hífens e páginas geradas de modo reverso. Estes pontos são tratados a seguir.
O uso de um limiar fixo que distingue um espaço entre palavras e entre fragmentos falha quando é utilizado fontes muito grandes ou muito pequenas. Nas fontes muito grandes, os espaços entre fragmentos são identificados como espaços entre palavras, logo a palavra torna-se vários caracteres individuais. Nas fontes muito pequenas, o contrário acontece e as palavras ficam todas juntas.
Uma heurística para resolver este problema é definir o limiar como uma fração do tamanho médio da fonte. Este tamanho é calculado divindo o tamanho do fragmento interpretado graficamente pelo número de caracteres do fragmento. Examinando histogramas de quebra como fração de caracter, Craig [NMRW98] define como um limiar de 30% do tamanho do caracter.
Uma diferença essencial entre a quebra de linha e a quebra de parágrafo é que a primeira ajuda a tornar o texto mais legível, mas não tem nada a ver com o conteúdo do texto, a segunda altera o conteúdo e sentido do texto, logo temos uma obrigação em manter as quebras de parágrafo coerentes.
Podemos distinguir dois tipos de quebras de parágrafo, mostrados na figura 5. O primeiro pressupõe que existem mais espaços entre parágrafos que entre linhas, como na figura 6(a). Se um espaço entre linhas excede o tamanho médio de quebra de linha, deve ser tratado como quebra de parágrafo. O segundo separa parágrafos marcados com indentação.
No tipo de indentação (figura 6(b)), a primeira linha do segundo parágrafo é indentada ao lado esquerdo, isto já é uma evidência de um novo parágrafo, entretanto devemos analisar outros pontos dentro da heurística para assegurar a quebra de parágrafo (considere os números a direita do texto):
Nas últimas duas restrições, é medido o tamanho do texto e não a distância entre as margens. Estas regras não são infalíveis, mas funcionam bem na prática.
Caracteres não-ASCII existem quando no arquivo PS é usado letras gregas, símbolos matemáticos e etc., logo para resolução deste problema possuímos duas soluções:
A hifenização acontece freqüentemente quando o texto está justificado a uma margem fixa a direita. Para sulucionarmos este problema, retiramos o hífen e concatenamos o fragmento que possuía o hifen com o próximo depois da quebra de linha.
As páginas dos documentos aparecem em ordem reversa, isto é utilizado para em impressoras, as páginas sairem já ordenadas, quando a impressora devolve a página com a face para cima.
Para detectarmos se o texto está em ordem reversa, números adjacentes a quebra de página são capturados e comparados entre si; se a ordem do número estiver crescendo ou decrescendo, podemos definir se é reverso ou não. Este método pode ser declarado confiável conforme [NMRW98], pois a decisão é tomada pela análise global e não pelos números a parte.
Dentre todas estas opções, as que se mostram disponíveis até hoje são as três últimas: pstotext, ps2ascii e prescript.
As nossas análises sobre estes programas vão utilizar testes sobre 15 artigos PS (23 MB) nos três programas: pstotext, ps2ascii e prescript, comparando dois dados importantes:
Podemos perceber pela figura 1 que o programa ps2ascii apresenta na média o resultado mais rápido.
Na figura 1, percebemos arquivos grandes que possuem um tempo de execução menor utilizando o mesmo programa. Devemos comparar os dados obtidos a cada tamanho de arquivo, já que o crescimento de tamanho de arquivos engloba várias outras variáveis que diferem o conteúdo como: um arquivo possui mais figuras e gráficos (que são ignorados no processo de extração), outro possui mais tabelas (que tem uma complexidade maior para o processo) e outras características que diferem no tempo de execução.
No aspecto robustez, o prescript suportou todas as características detalhadas neste relatório (caracteres não-ASCII, retirar hifenização, quebras de linha e parágrafos, etc.), o ps2ascii suportou todas as características, com exceção da quebra de linha e o pstotext não suportou caracteres não-ASCII e retirar hifenização.
O Prescript apresenta-se como a melhor solução para extração de texto em arquivos PS no quesito robustez, mas apresenta-se lento. Além de não conseguir processar certos arquivos que foram gerados a partir de drives de impressoras PS, enquanto os outros suportaram estes arquivos. Entretando no quesito rapidez, o ps2ascii apresenta maior rapidez apesar do texto ser um pouco menos fiel (falta de quebra de linha).
 |
 |
This document was generated using the LaTeX2HTML translator Version 2K.1beta (1.48)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html -split 0 -local_icons seminario.tex
The translation was initiated by on 2002-09-30