André Luiz de Oliveira
aldo@dcc.ufmg.br -
Luiz Henrique Gomes
lhg@dcc.ufmg.br -
Renan Oliveira da Cunha
renan@dcc.ufmg.br -
Departamento de Ciência da Computação
Universidade Federal de Minas Gerais
Belo Horizonte - MG - Brasil
Resumo - A distribuição de conteúdo na Internet tem migrado de uma arquitetura onde os objetos são armazenados em um único servidor para uma arquitetura onde os objetos são replicados em servidores distribuídos geograficamente.
Neste caso, os clientes acessam transparentemente a cópia mais próxima do objeto desejado, melhorando o desempenho do sistema. Neste trabalho apresentamos um modelo para o estudo destas redes de distribuição de conteúdo, conhecidas como CDN's (Content Distribution Networks). Utilizando este modelo, avaliamos quatro heurísticas para a replicação de objetos através de simulação. Os resultados dos experimentos mostram o ganho significativo de desempenho do sistema ao utilizarmos qualquer um dos algoritmos. Além disso, os melhores resultados foram obtidos quando todos os servidores trabalham cooperativamente para a replicação dos objetos.
![]()
Abstract - Content distribution on the Internet is moving from an architecture where objects are placed on a single, designated server to an architecture where objects are replicated on geographically distributed servers.
With this new architecture, clients can transparently access a nearby copy of an object.
In this paper we propose a model for studying these Content Distribution Networks (CDNs).
Using this model, we avaliate four different heuristics for objects replication. The results of the experiments show
the significant improvement of the system performance through the utilisation of any algorithm. Furthermore, the
best results were obtained with heuristics that have all the CDN servers cooperating in making the replication decisions.
Nesse contexto, foram desenvolvidas as Redes de Distribuição de Conteúdo (CDN - Content Distribution Network). Uma CDN consiste em uma vasta rede de servidores, espalhados por uma área geográfica e ligados através de uma rede proprietária. O conteúdo dos sites Clientes são replicados pelos servidores, de modo que, ao receber uma requisição, a rede escolhe, utilizando algum mecanismo de despacho de requisições, a melhor réplica para atender àquela solicitação [1].
Os trabalhos relacionados foram analisados na seção 2. Na seção 3, será feita uma descrição e contextualização do problema de replicação de objetos em CDNs. A seção 4 descreve um modelo matemático para o problema que é utilizado na seção 5 para mostrar que o problema tratado é NP-Completo. A seção 6 apresenta uma descrição e os pseudo-códigos das heurísticas que serão avaliadas. Na seção 7, é descrito o modelo de simulação utilizado. Os resultados da simulação são avaliados na seção 8 e, na seção 9, encontram-se as conclusões e os trabalhos futuros.
No trabalho [3] foi apresentado uma comparação de desempenho entre CDNs, tendo sido utilizado um método empírico para fazer tal comparação. Neste trabalho constatou-se que 98% dos objetos servidos pelas CDNs são imagens, representando 40% do total de bytes servidos pelas CDNs.
Em [4] foram apresentadas diversas técnicas para despacho de requisições entre sites Web. Embora o enfoque do trabalho não seja o despacho de requisições em CDNs, ele descreve todas as técnicas geralmente utilizadas pelas CDNs.
Em [5] está descrita uma arquitetura para redirecionamento de requisições entre CDNs. Também são apresentadas motivações para a interoperação de CDNs, e uma avaliação do desempenho de um sistema para a realização deste redirecionamento.
Um dos problemas das Web farms é que o tempo de resposta, devido ao congestionamento da Internet, não é afetado pelo seu uso. Somente o tempo de resposta do servidor Web propriamente dito é reduzido.
Web caches têm sido utilizados com muito sucesso para reduzir o tempo de resposta devido ao congestionamento da Internet, indiferentemente dos pontos da rede em que se localizam e do número de usuários de um site Web [6].
As CDNs surgem com o objetivo de minimizar as limitações das duas tecnologias citadas acima. Utilizando CDNs, a distância entre os usuários e os sites Web diminui pois, dentro da área geográfica atendida por esta, sempre será possível encontrar um servidor mais próximo do Cliente em termos de latência de rede, do que o servidor original. Além disso, como o atendimento aos usuários será feito por um número muito maior de servidores, a carga do servidor original será reduzida e, consequentemente, o tempo de resposta dos servidores Web.
Atualmente, diversos sites Web são Clientes de CDNs comerciais (ex. Akamai [7], Digital Island [8] etc). O objetivo de uma Rede de Distribuição de Conteúdo comercial não se restringe à redução do tempo de resposta percebidos pelos usuários de seus Clientes, abrangendo também a redução da carga da rede e dos servidores de seus Clientes.
Como CDNs consistem de uma tecnologia relativamente nova no contexto da Internet, existem diversos problemas relacionados à esta tecnologia ainda não resolvidos. Um desses problemas trata-se da escolha do servidor para atender a requisição.
Este problema consiste em descobrir qual é o melhor servidor para atender a uma requisição de um usuário, ou seja, o servidor de despacho de requisições da CDN recebe uma requisição de um usuário e baseado em informações sobre os servidores e o cliente ele determinará qual servidor irá atender àquela requisição [4].
Outro problema é a verificação da atualidade dos objetos armazenados em um servidor da CDN. Os diversos servidores da CDN precisam saber se as cópias que eles detêm dos objetos foram ou não modificadas no servidor original. Portanto, eles necessitam de um mecanismo de comunicação, de modo que cópias desatualizadas sejam reconhecidas e, consequentemente, não sejam fornecidas aos usuários [9].
Mais recentemente, surgiu a necessidade de cooperação entre CDNs, de modo que um Cliente possa ser atendido por diversas CDNs que, em geral, operam em áreas distintas. Sendo assim, surgiu um novo problema para as redes CDNs. Que consiste no problema de escolha do melhor servidor para atender a uma determinada requisição de forma que essa decisão seja tomada em conjunto pelos servidores de mais de uma CDN [5].
O problema estudado neste trabalho consiste da replicação de objetos entre os servidores dos Clientes e os da CDN. Estas réplicas podem ser realizadas de duas formas [9]: cópia prévia - neste caso, faz-se uma cópia dos objetos nos diversos servidores da CDN antes que eles seja requisitados, baseado em um algoritmo qualquer; e cópia dinâmica - neste caso, a cópia é feita na hora em que a requisição é efetuada. O objeto é repassado ao Cliente e armazenado no servidor ao mesmo tempo.

O objetivo das heurísticas é, encontrar uma matriz de alocação X de modo que tenhamos que percorrer o menor número de hops inter-AS possível para o atendimento das requisições dos usuários, ou seja, para que o atendimento de uma requisição do usuário tenha que passar pelo menor número possível de AS's [2]. O número médio de hops que uma requisição deve atravessar vinda do ASi é dada por:
A prova de que o problema é NP-Completo será feita em duas etapas [10] [2]:
Provaremos que o problema é NP: dada uma matriz de posicionamento X, podemos verificar em tempo polinomial que este posicionamento resulta em um custo médio menor ou igual a T. Para tanto, basta calcular os valores sij e dij(x) e utilizar a fórmula acima.
Mostraremos uma redução polinomial do problema da mochila no nosso problema:
façamos S1=S; Si=0; ![]() ;
; ![]() ;
; ![]() ;
pji=p;
;
pji=p; ![]() e
e ![]() .Ou seja, nós temos apenas um AS onde replicar os objetos. Todos os AS's têm
a mesma taxa de acesso e todos os objetos são igualmente populares.
.Ou seja, nós temos apenas um AS onde replicar os objetos. Todos os AS's têm
a mesma taxa de acesso e todos os objetos são igualmente populares.
Como cada objeto j está sempre disponível no AS de origem, o custo de buscar um objeto j para um Cliente do ASi é dij(x0). Dado que os Clientes sempre vão à cópia mais próxima para atender a uma requisição, colocar cópia dos objetos no único AS disponível deverá sempre reduzir o tempo de acesso a um objeto, e portanto
Desta forma, podemos descrever o problema da seguinte forma:
Todas as heurísticas apresentadas trabalham com cópias prévias, citadas na seção 3. Porém, com pequenas alterações, é possível utilizá-las para trabalhar com cópias dinâmicas.
Para a descrição dos algoritmos, utilizaremos a seguinte notação: Si - espaço disponível no ASi para armazenamento de cópias, B - cojunto de objetos disponíveis para réplica, J - número total de objetos, I - número total de AS's e AS_OBJ - conjunto de todos os objetos copiados no ASi.
Random - Neste algoritmo os objetos são atribuídos aos AS's de forma aleatória, sendo
respeitadas as restrições de armazenamento. É utilizada uma distribuição uniforme
de probabilidade para atribuir os objetos aos AS's. Um objeto pode estar armazenado
em diversos nodos, porém nunca um nodo terá mais de uma cópia de um objeto [2] .
for (i=1;i<=I;i++){
AS_OBJ[i].size = 0;
while(AS_OBJ[i].size<S[i])
{
obj=random();
if (obj not in AS_OBJ[i].objs) and
(obj.size+AS_OBJ[i].size<=S[i])
{
AS_OBJ[i].objs=AS_OBJ[i].objs U {obj};
AS_OBJ[i].size+=obj.size;
}
}
}
Popularity - Nesta heurística, cada nodo armazena os objetos mais populares
entre seus Clientes. Os nodos ordenam os objetos em ordem decrescente de
popularidade e armazena o maior número de objetos que conseguir, respeitando
a ordem de popularidade e sua restrição de capacidade de armazenamento [2] .
Um nodo pode estimar a popularidade de um objeto observando as requisições que ele recebe
dos seus Clientes. Neste caso, o nodo não precisa de informações de outros nodos para
decidir quais objetos vai armazenar.
for (i=1;i<=I;i++){
AS_OBJ[i].size = 0;
while (AS_OBJ[i].size<S[i]){
obj=ObtemMaisPopular(B[i],i);
if (obj not in AS_OBJ[i].objs) and
(AS_OBJ[i].size+obj.size<=S[i]){
AS_OBJ[i].objs=AS_OBJ[i].objs U {obj};
AS_OBJ[i].size+=obj.size;
}
}
}
Greedy-Single - Nesta heurística, cada nodo i calcula
Este custo representa a contribuição individual do objeto j em (1), considerando o posicionamento inicial dos objetos x0. Após calcular Cij para todos os objetos, ordena-se os objetos em ordem decrescente de Cij, então armazena-se os objetos observando a ordem obtida e a restrição de espaço de cada AS. Desta forma, o AS precisa de informação da CDN para calcular dij. Como o custo Cij é calculado somente uma vez, e com relação ao posicionamento inicial de cada objeto, a contribuição das cópias dos objetos para replicação dos próximos objetos, ainda não replicados, não é considerado [2] .
Logo, cada nodo armazena os objetos de forma independente dos outros nodos, ou seja, não
existe cooperação entre os nodos da CDN. O algoritmo está descrito abaixo.
for (i=1;i<=I;i++)
for (j=1;j<=J;j++)
C[i][j]=P[i][j]*d[i][j](X[0]);
for (i=1;i<=I;i++){
AS_OBJ[i].size = 0;
while (AS_OBJ[i].size<S[i]){
obj = Max(C[i]);
if (AS_OBJ[i].size+obj.size<=S[i]){
AS_OBJ[i].objs=AS_OBJ[i].objs U {obj};
AS_OBJ[i].size += obj.size;
}
}
}
Greedy-Global Nesta heurística, a CDN primeiro calcula
Então a CDN escolhe o maior Cij e armazena o objeto j no
nodo i. Com esta replicação, gera-se uma nova matriz de posicionamento X1. Depois disto, a
CDN recalcula os Cij baseados nessa nova matriz de posicionamento e repete o
processo anterior até que todos os AS's tenham sido preenchido com todos os objetos
que puderem armazenar, respeitando sua restrição de espaço [2]. O algoritmo está descrito abaixo.
for (i=1;i<=I;i++) AS_OBJ[i].size = 0;
k = 0;
CalculaCij(X[0]);
while (Existe(AS_OBJ[i].size < S[i])){
MaxCij( &obj, &i);
if (AS_OBJ[i].size+obj.size<=S[i]){
AS_OBJ[i].objs = AS_OBJ[i].objs U {obj};
AS_OBJ[i].size += obj.size;
}
k++;
CalculaCij(X[k]);
}
A topologia de rede construída foi composta por 6 (seis) AS's e 6 (seis) servidores da CDN. A métrica utilizada em nossa avaliação, número de hops, nos permite ficar independente de problemas tais como a latência de rede, simplificando a avaliação efetuada.
O posicionamento inicial dos objetos nos servidores originais foi aleatório. Ou seja, primeiramente, geramos um determinada quantidade de objetos e os distribuímos aleatoriamente entre os diversos servidores. Foi considerado que todo o conteúdo do servidor original poderia ser replicado em algum servidor da CDN.
Cada servidor da CDN possui um buffer restrito para o armazenamento dos objetos. Este buffer variou de 0% a 50% do tamanho total de objetos em nossos experimentos. Ao considerarmos que o buffer pode armazenar 0% da quantidade total de objetos, estamos avaliando o comportamento da rede para o caso onde não existe uma rede de distribuição de conteúdo.
Para modelar o tamanho dos objetos utilizamos a distribuição de Paretto [11], com
a limitação que o maior valor gerado é, no máximo, cinco vezes o tamanho médio dos
objetos (fixado em 14 kb). Para definir a popularidade de cada objeto, utilizamos a distribuição
de Zipf [12] ![]() (Valores de
(Valores de ![]() , 0.6, 0.8 e 1.0)
, 0.6, 0.8 e 1.0) ![]() . Como vimos anteriormente, a popularidade de
um objeto é importante para o cálculo de distribuição nas heurísticas popularity,
greedy-single e greedy-global.
. Como vimos anteriormente, a popularidade de
um objeto é importante para o cálculo de distribuição nas heurísticas popularity,
greedy-single e greedy-global.
A chegada de requisições em cada servidor segue uma distribuição uniforme. Optamos por considerar que cada servidor de um AS recebe o mesmo número de requisições. Desta forma, os servidores de cada AS apresentaram um comportamento semelhante, facilitando a análise final dos resultados obtidos. Os resultados de nossos experimentos encontram-se na seção 8.
Para cada heurística, executamos os experimentos variando o valor do parâmetro beta da distribuição de Zipf (utilizada para modelar a popularidade dos objetos), o tamanho do buffer de cada servidor da CDN e o número de objetos armazenados nos servidores dos AS's.
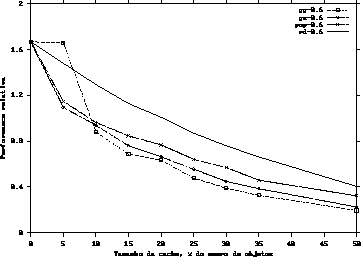
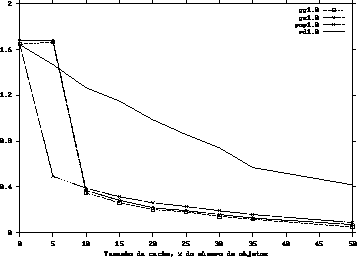
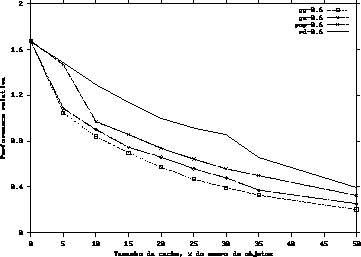
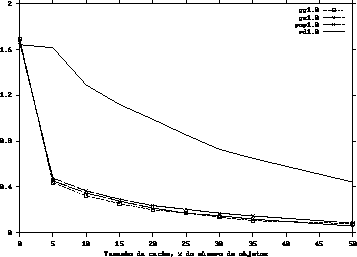
Como podemos observar através dos gráficos 1, 2, 3 e 4, um pequeno acréscimo no tamanho do buffer , inicialmente, provoca um ganho significativo de desempenho do sistema. Entretanto, quando o buffer da CDN ultrapassa 35% da quantidade total de objetos, o ganho de desempenho passar a ser pouco significativo, decorrência do comportamento logarítmico dos gráficos.
É interessante observarmos que quando o parâmetro ![]() da distribuição de Zipf é
igual a 1 (um), os algoritmos greedy-global, greedy-single e popularity
apresentam um comportamento muito parecido pois, neste caso, a distribuição de Zipf
se transforma numa distribuição uniforme.
da distribuição de Zipf é
igual a 1 (um), os algoritmos greedy-global, greedy-single e popularity
apresentam um comportamento muito parecido pois, neste caso, a distribuição de Zipf
se transforma numa distribuição uniforme.
Como pode ser visto nos gráficos, quando ![]() tem valor 0.6, a CDN é mais efetiva, ou seja, a contribuição
para a redução do tempo de resposta dos usuários é maior. Isto ocorre porque quanto maior o
valor de
tem valor 0.6, a CDN é mais efetiva, ou seja, a contribuição
para a redução do tempo de resposta dos usuários é maior. Isto ocorre porque quanto maior o
valor de ![]() (
(![]() ), menos objetos terão uma alta popularidade, fazendo como que a replicação
dos mesmos resulte em uma redução significativa do tempo de resposta dos usuários.
Nestes casos, onde um número menor de objetos tem uma baixa popularidade, a heurística random apresenta um
desempenho pior, e no caso desta heurística replicar alguns destes objetos, a CDN contribuirá muito
pouco para a redução do tempo de resposta dos usuários.
), menos objetos terão uma alta popularidade, fazendo como que a replicação
dos mesmos resulte em uma redução significativa do tempo de resposta dos usuários.
Nestes casos, onde um número menor de objetos tem uma baixa popularidade, a heurística random apresenta um
desempenho pior, e no caso desta heurística replicar alguns destes objetos, a CDN contribuirá muito
pouco para a redução do tempo de resposta dos usuários.
Observamos, por fim, que a heurística greedy-global obteve o melhor desempenho em todos os testes, e que as heuríticas popularity e greed-single tiveram comportamentos parecidos. Concluímos, ainda, que a heurística random tem o pior comportamento em todos os testes.
Avaliamos quatro heurísticas para a replicação de objetos, utilizando o modelo proposto, e verificamos que a utilização dos mesmos implica num ganho significativo de desempenho do sistema. Ou seja, a utilização de técnicas de distribuição de objetos diminuem sensivelmente o tempo de resposta a uma dada requisição, assim como a carga de trabalho do servidor original.
Nossos resultados mostraram que a heurística Greedy-Global, onde os servidores da CDN trabalham cooperativamente, apresentou o melhor desempenho dentre as heurísticas avaliadas. Embora os algoritmos popularity e greedy-single tenham apresentado comportamento parecido acreditamos que, à medida que o número de nodos da rede CDN aumente, os resultados obtidos para estas heurísticas tendam a se distanciar.
A área de pesquisa relativa à avaliação e desenvolvimento de novos algoritmos para redes de distribuição de conteúdo possui um enorme potencial. Como trabalhos futuros, iremos investigar mais detalhadamente os mecanismos de cooperação entre os servidores, e avaliar o desempenho dos algoritmos quando consideramos uma replicação dinâmica dos objetos. Também pretendemos ampliar nosso modelo para que ele modele mais precisamente a topologia da internet e cosidere novos parâmetros, tais como o tráfego da rede e a carga dos servidores, possibilitando, desta maneira, que sejam estabelecidos limites inferiores para o desempenho destes tipos de algoritmos.
This document was generated using the LaTeX2HTML translator Version 97.1 (release) (July 13th, 1997)
Copyright © 1993, 1994, 1995, 1996, 1997, Nikos Drakos, Computer Based Learning Unit, University of Leeds.
The command line arguments were:
latex2html -split 0 sem.tex.
The translation was initiated by Luiz Henrique Gomes on 9/25/2002