Erickson R. Nascimento
Research Projects
Semantic HyperlapseIn this project, we deal with a central challenge that is to make egocentric videos watchable. First person videos are generally long-running streams with unedited content, which make them boring and visually unpalatable. In this project we propose a novel methodology to compose the new fast-forward video by selecting frames in a smart manner and based in the semantic information extracted from images.More information about the Semantic Hyperlapse project. |
|
|
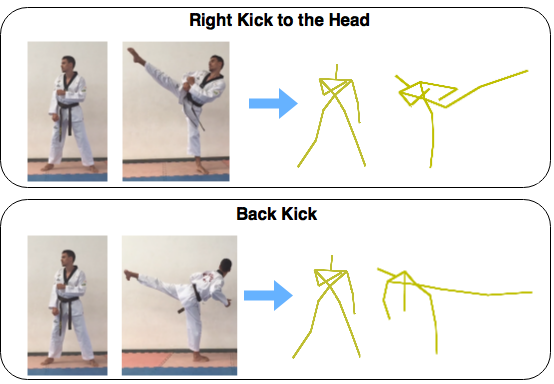
High Performance Moves RecognitionCompared with daily human gestures, moves in high performance sports are faster and have low inter-class variability, which produce noisy features and ambiguity. We present a discriminative key pose-based approach for moves recognition and segmentation of training sequences for high performance sports.Dataset and more information about high performance moves recognition. |
Efficient 3D model estimation methodology for large datasetsThe advent of digital cameras heralded many possibilities of structure and shape re- covery from imagery that are quickly and inexpensively acquired by such devices. In this work we propose an efficient approach based on structure from motion and multi-view stereo reconstruction techniques to automatically generate DEM - Digital Elevation Models - from aerial images and also 3D models in general. |
|

|
Image and Depth Super-ResolutionWith the purpose of increasing data resolution, at the same time reducing noise and filling the holes in the depth maps, in this work we propose a method that combines depth fusion and image reconstruction in a super- resolution framework.Download the conference paper (Best Computer Graphics Paper Award of SIBGRAPI 2015). |

|
Keypoint descriptor extraction for RGB-D dataAt the core of a myriad of tasks such as object recognition, tridimensional recon- struction and alignment resides the critical problem of correspondence. We introduce BRAND descriptors that efficiently combine appearance and geometrical shape information from RGB-D images, and are largely invariant to rotation, illumination changes and scale transformations.Download the journal paper. |


